Why is there a data engineer shortage?
- High Demand and Rapid Growth: The increasing reliance on data-driven decision-making and the rise of big data technologies have created a surge in demand for skilled data engineers.
- Skill Gap and Specialization: Data engineering requires a unique blend of technical skills, and finding individuals with the right combination of programming, database management, and cloud computing expertise can be challenging.
- Competition from Other Data Roles: The allure of data science and other data-related roles has attracted professionals, leading to a talent shortage in the data engineering field.
How big is the data engineer shortage?
💡 "In Europe there are 32K data engineers and 48K open positions to hire one. In the US the ratio is 41K to 79K" Source: Linkedin data analysis blog post
Well that doesn’t look too bad - if only we could all be about 2x as efficient :)
Bridging the gap: How to make your data engineers 2x more efficient?
There are 2 ways to make the data engineers more efficient:
Option 1: Give them more to do, tell them how to do their jobs better!
For some reason, this doesn’t work out great. All the great minds of our generation told us we should be more like them
- do more architecture;
- learn more tech;
- use this new toy!
- learn this paradigm.
- take a step back and consider your career choices.
- write more tests;
- test the tests!
- analyse the tests :[
- write a paper about the tests...
- do all that while alerts go off 24/7 and you are the bottleneck for everyone downstream, analysts and business people screaming. (┛ಠ_ಠ)┛彡┻━┻
“I can't do what ten people tell me to do. So I guess I'll remain the same”
- Otis Redding, Sittin' On The Dock Of The Bay
Option 2: Take away unproductive work
A data engineer has a pretty limited task repertoire - so could we give some of their work to roles we can hire?
Let’s see what a data engineer does, according to GPT:
- Data curation: Ensuring data quality, integrity, and consistency by performing data profiling, cleaning, transformation, and validation tasks.
- Collaboration with analysts: Working closely with data analysts to understand their requirements, provide them with clean and structured data, and assist in data exploration and analysis.
- Collaboration with DWH architects: Collaborating with data warehouse architects to design and optimize data models, schemas, and data pipelines for efficient data storage and retrieval.
- Collaboration with governance managers: Partnering with governance managers to ensure compliance with data governance policies, standards, and regulations, including data privacy, security, and data lifecycle management.
- Structuring and loading: Designing and developing data pipelines, ETL processes, and workflows to extract, transform, and load data from various sources into the target data structures.
- Performance optimization: Identifying and implementing optimizations to enhance data processing and query performance, such as indexing, partitioning, and data caching.
- Data documentation: Documenting data structures, data lineage, and metadata to facilitate understanding, collaboration, and data governance efforts.
- Data troubleshooting: Investigating and resolving data-related issues, troubleshooting data anomalies, and providing support to resolve data-related incidents or problems.
- Data collaboration and sharing: Facilitating data collaboration and sharing across teams, ensuring data accessibility, and promoting data-driven decision-making within the organization.
- Continuous improvement: Staying updated with emerging technologies, industry trends, and best practices in data engineering, and actively seeking opportunities to improve data processes, quality, and efficiency.
Let’s get a back of the napkin estimation of how much time they spend on those areas
Here’s an approximation as offered by GPT. Of course, actual numbers depend on the maturity of your team and their unique challenges.
- Collaboration with others (including data curation): Approximately 40-60% of their working hours. This includes tasks such as collaborating with team members, understanding requirements, data curation activities, participating in meetings, and coordinating data-related activities.
- Data analysis: Around 10-30% of their working hours. This involves supporting data exploration, providing insights, and assisting analysts in understanding and extracting value from the data.
- Technical problem-solving (structuring, maintenance, optimization): Roughly 30-50% of their working hours. This includes solving data structuring problems, maintaining existing data structures, optimizing data pipelines, troubleshooting technical issues, and continuously improving processes.
By looking at it this way, solutions become clear:
- Let someone else do curation. Analysts could talk directly to producers. By removing the middle man, you improve speed and quality of the process too.
- Automate data structuring: While this is not as time consuming as the collaboration, it’s the second most time consuming process.
- Let analyst do exploration of structured data at curation, not before load. This is a minor optimisation, but 10-30% is still very significant towards our goal of reducing workload by 50%.
How much of their time could be saved?
Chat GPT thinks:
it is reasonable to expect significant time savings with the following estimates:
- Automation of Structuring and Maintenance: By automating the structuring and maintenance of data, data engineers can save 30-50% or more of their time previously spent on these tasks. This includes activities like schema evolution, data transformation, and pipeline optimization, which can be streamlined through automation.
- Analysts and Producers Handling Curation: Shifting the responsibility of data curation to analysts and producers can save an additional 10-30% of the data engineer's time. This includes tasks such as data cleaning, data validation, and data quality assurance, which can be effectively performed by individuals closer to the data and its context.
It's important to note that these estimates are approximate and can vary based on the specific circumstances and skill sets within the team.
40-80% of a data engineer’s time could be spared
💡 40-80% of a data engineer’s time could be sparedTo achieve that,
- Automate data structuring.
- Govern the data without the data engineer.
- Let analysts explore data as part of curation, instead of asking data engineers to do it.
This looks good enough for solving the talent shortage. Not only that, but doing things this way lets your team focus on what they do best.
A recipe to do it
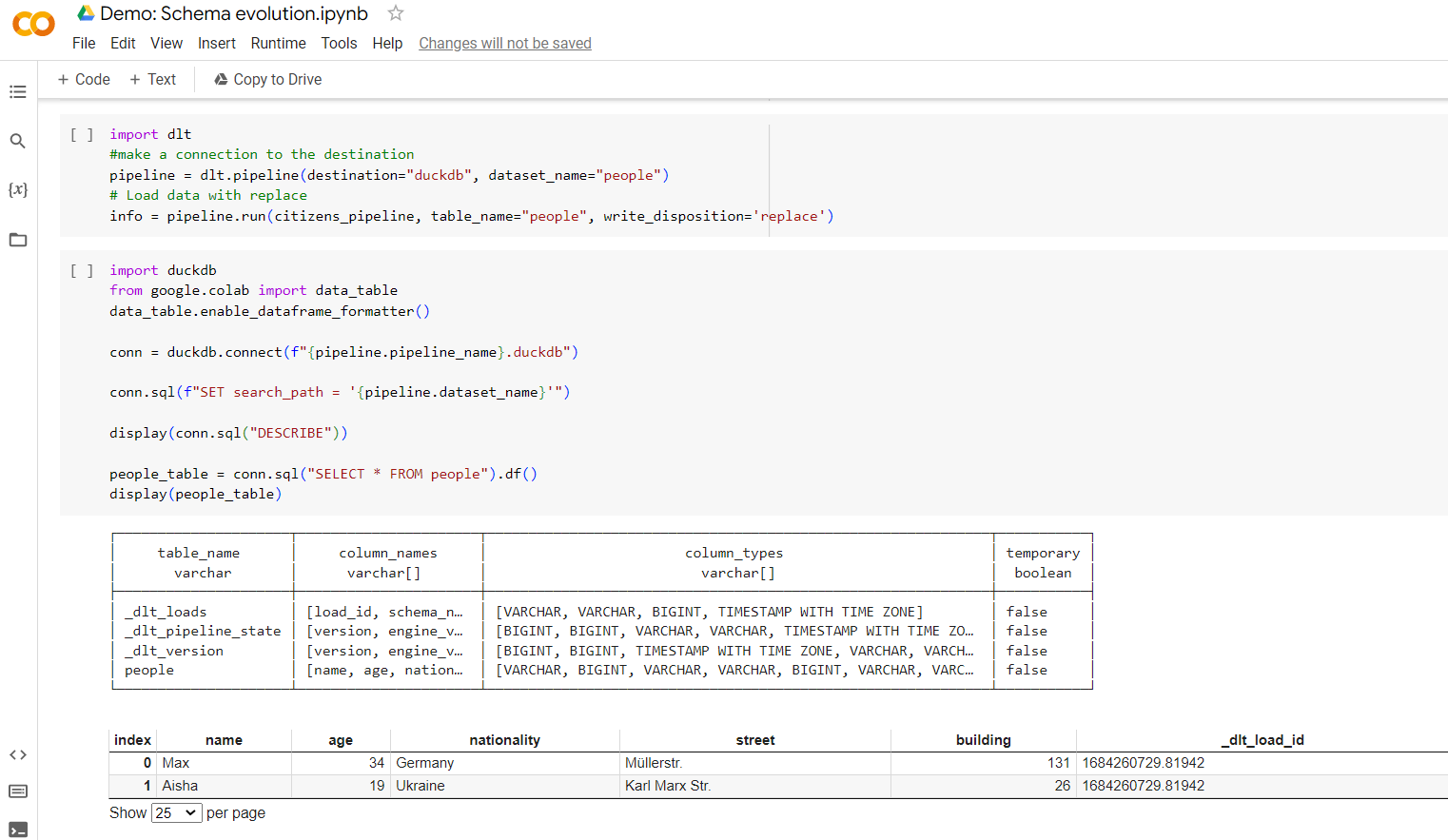
- Use something with schema inference and evolution to load your data.
- Notify stakeholders and producers of data changes, so they can curate it.
- Don’t explore json with data engineers - let analyst explore structured data.
Ready to stop the pain? Read this explainer on how to do schema evolution with dlt. Want to discuss? Join our slack.